KI-Agenten erstellen: Die ehrliche Entscheidungshilfe für den deutschen Mittelstand

KI-Agenten erstellen ist 2026 kein Tooling-Problem mehr. Die technische Hürde ist niedrig genug, dass eine Person mit ein paar Stunden Einarbeitung einen funktionierenden Agenten bauen kann. Was hoch geblieben ist, sind die Folgekosten der falschen Tool-Entscheidung. Wer im Mai 2026 noch alles auf der OpenAI Assistants API aufsetzt, hat im August 2026 den Sunset zu migrieren. Wer auf AutoGen setzt, baut auf einem Framework, das Microsoft selbst in den Maintenance-Modus geschickt hat. Wer im Mittelstand mit Make.com startet und nicht die Credit-Mechanik kennt, bekommt die Rechnung erst nach dem dritten Produktionsmonat.
Dieser Beitrag schaut tool-agnostisch auf die Frage, wie man 2026 im deutschen Mittelstand einen Agenten baut, der mehr ist als ein Hello-World-Demo. Er vergleicht ehrlich die drei Plattform- Kategorien (No-/Low-Code, Pro-Code-Frameworks, Hosted-Services), zeigt für vier konkrete Use-Cases die jeweils sinnvollste Wahl und listet die neun Bausteine auf, die ein Agent in Produktion braucht. Wer tiefer in eine spezifische Plattform einsteigen will, findet die Spokes verlinkt: für n8n die n8n-Praxisanleitung für KI-Agenten und für das theoretische Fundament den Bauplan für KI-Agents nach Anthropic. Wer lieber an konkreten Anwendungsfällen entlang denkt, findet im Beispielkatalog für KI-Agenten praxisnahe Use-Cases für Mittelstand und Großhandel.
80 Prozent der gescheiterten Mittelstands-Pilotprojekte haben dasselbe Muster: Tool wurde vor der Strategie gewählt. Zwei Fragen klären die meisten Verirrungen, bevor sie passieren.
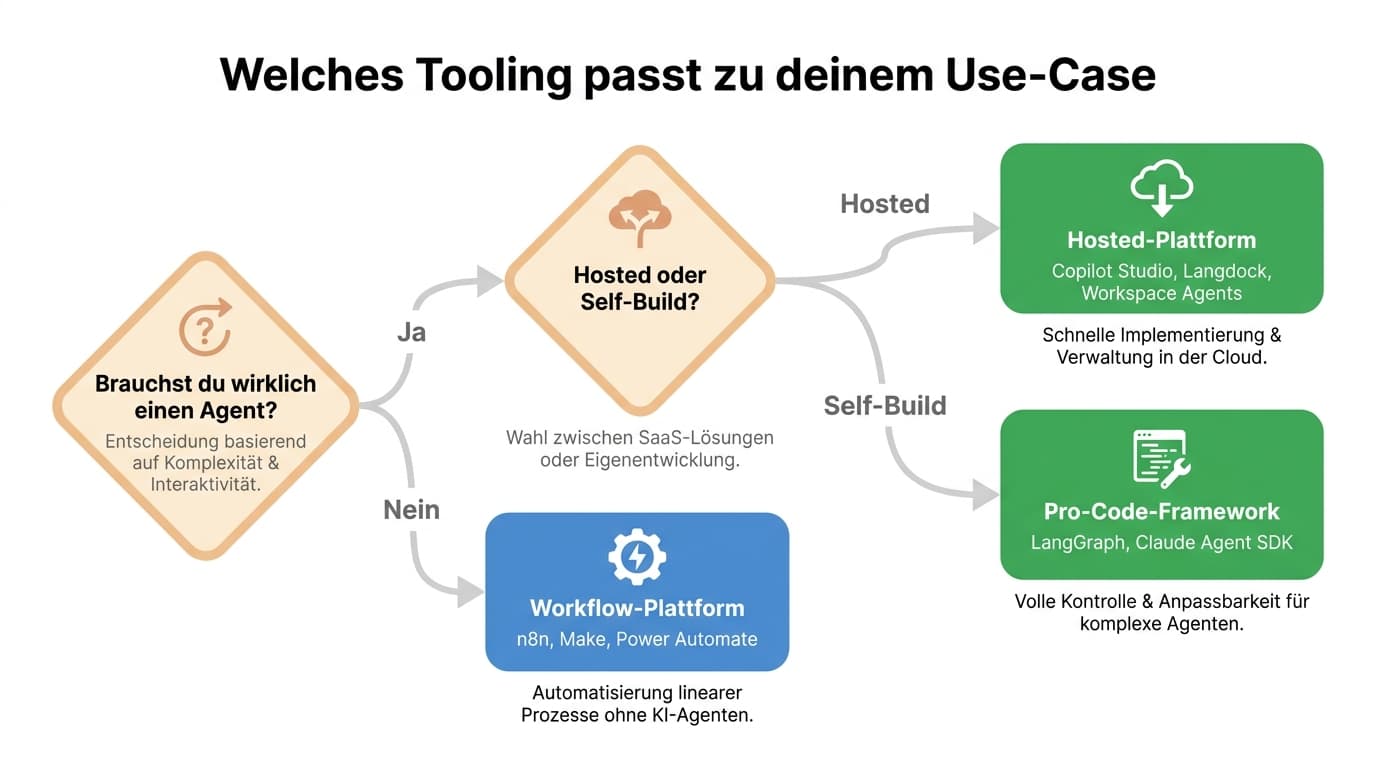
Ein Agent ist ein LLM, das selbst entscheidet, welche Werkzeuge es in welcher Reihenfolge benutzt. Das klingt mächtig und ist es für offene Aufgaben (Recherche, mehrstufige Reklamationsbearbei- tung, Sales-Outreach). Für 70 Prozent der typischen Mittelstands- Use-Cases reicht aber ein deterministischer Workflow mit einem oder zwei LLM-Aufrufen vollständig aus. Eingangsrechnung extrahieren und vorkontieren? Workflow. Bestelleingang aus E-Mail parsen und ins ERP? Workflow. Reklamation routen und taggen? Workflow. Anthropic empfiehlt in der Doktrin Building Effective Agents: Wenn eine Prompt-Chain das Problem löst, baue keine Agent-Architektur. Die häufigste Fehlentscheidung beim Agentic-Design ist der Griff zu Multi-Agent-Systemen, wenn drei gut formulierte Prompts in einer Kette ausgereicht hätten.
Tatsächlich agentisch wird ein Use-Case erst, wenn der Pfad nicht vorhersehbar ist. Eine Recherche, die je nach Quelle drei, fünf oder zehn Tool-Aufrufe braucht. Eine Lieferanten-Risiko- Bewertung, die je nach News-Lage andere Datenpunkte zieht. Ein Mitarbeiter-Chatbot, der je nach Frage SharePoint, das Wiki oder das ERP anzapft. Wenn dein Use-Case eine ablaufdiagrammtaugliche Struktur hat, ist es ein Workflow.
Die zweite Frage ist Make-or-Buy. Hosted-Plattformen wie Microsoft Copilot Studio, Langdock oder die ChatGPT Workspace Agents geben dir einen vorkonfigurierten Stack: Memory, Connectoren, Admin-Konsole, Logging. Du gibst Vendor-Lock-in, Preistransparenz und Tiefe der Integration auf, bekommst dafür Geschwindigkeit. Selbst bauen mit n8n, LangGraph oder dem Claude Agent SDK kostet mehr Engineering, aber du behältst Daten, Kosten und Architektur in der Hand. Für die meisten Mittelständler ist eine Mischform die richtige Antwort: Workflow-Orchestrator selbst hosten (n8n auf einer EU-Maschine), darin Agent-Knoten verwenden, LLM über AWS Bedrock Frankfurt oder Azure OpenAI Sweden Central. Hosted- Services sinnvoll für klar umrissene Wissens-Chatbots oder MS-365-zentrierte Office-Automation, weniger sinnvoll für tiefe ERP-Integration.
2026 lassen sich Agent-Plattformen in vier Kategorien einteilen. Jede deckt einen anderen Punkt im Make-or-Buy-Spektrum ab.
n8n, Make.com, Microsoft Power Automate und Zapier bieten alle inzwischen einen AI-Agent-Node oder ein vergleichbares Modul. Du baust visuell, der Agent ist ein Knoten in einem größeren Workflow, der Trigger, Vorverarbeitung und Folgeaktionen orchestriert. Die Plattform kümmert sich um Credentials, Logging, Retries und Connectoren zu hundert anderen Systemen. Das ist der schnellste Weg für deutsche Mittelständler, weil die ERP-, Mail- und CRM-Anbindung in der Realität 60 bis 80 Prozent des Aufwands ausmacht und genau hier diese Plattformen stark sind.
n8n ist der Default für DACH-Mittelständler mit Self-Host-Anforderung. Open Source (fair-code), eine Cloud- Variante in Azure Frankfurt für 24 Euro pro Monat im Starter- Plan, und seit April 2026 nur noch Executions statt Workflow- Limits in der Abrechnung. Make.com ist visuell etwas eingänglicher, hat 3.000 plus App-Konnektoren, kostet im Credit-Modell aber 43 bis 50 Credits pro AI-Agent-Execution gegenüber wenigen Credits für klassische Szenarien. Power Automate ist die natürliche Wahl, wenn der Stack ohnehin M365-zentriert ist und Business Central oder Dynamics im Spiel ist. Zapier Agents (GA seit Mai 2025) sind US-Hosting-Default und für deutsche Mittelständler oft DSGVO-kritisch.
LangChain mit LangGraph 1.0 (stable seit Q4 2025) ist 2026 der Industrie-Default für produktive Agenten in Custom-Code-Stacks. Durable State, Checkpointing, Time-Travel-Debugging und eingebaute Human-in-the-Loop-Patterns sind erstklassige Features. Uber, LinkedIn, Klarna setzen es ein. Die Lernkurve ist steil, Python- oder TypeScript-Kenntnisse Pflicht. Wer im Mittelstand keine eigenen Entwickler hat, ist hier falsch.
Das Claude Agent SDK von Anthropic bündelt Tool Use, Computer Use und Skills in einem kohärenten Framework. Mit Programmatic Tool Calling lässt sich Tool-Orchestrierung im generierten Code abbilden, was Token-Roundtrips und Latenz spart. Das Tool Search Tool erlaubt 10.000 plus Tools im Agenten, ohne das Context Window zu sprengen. Anthropic Skills sind seit Oktober 2025 ein offener Standard, von Microsoft VS Code, GitHub, Cursor und Goose adoptiert.
Die OpenAI Responses API und Conversations API ist der Nachfolger der Assistants API, die am 26. August 2026 abgeschaltet wird. Wer heute auf Assistants baut, plant entweder noch dieses Quartal die Migration oder akzeptiert die Notabschaltung. AutoGen ist seit Anfang 2026 in Maintenance, Microsoft empfiehlt neue Projekte auf dem Microsoft Agent Framework. CrewAI bleibt einsteigerfreundlich für Multi-Agent-Prototypen, ist aber im Production-Mittelstand eher Nische.
Microsoft Copilot Studio ist 2026 die natürliche Wahl für MS-365-zentrierte Unternehmen. Tiefe Integration in Power Platform, Dataverse als Memory-Backend, native MCP- Konnektoren und Enterprise-Admin-Controls. Die Pricing-Logik hat eine Falle: ein Capacity Pack kostet 200 USD pro Monat für 25.000 Credits, ein Script-Antwort verbraucht 1 Credit, eine Reasoning-Antwort 100 Credits. Wer das Mengengerüst nicht kennt, kalkuliert sich um Faktor 100 schief. ChatGPT Workspace Agents (April 2026 gelauncht) sind der Nachfolger der Custom GPTs mit nativen Konnektoren in Slack, Drive, Salesforce, Notion und Atlassian. Hosting ist US-Default mit Azure-Frankfurt- Option für Enterprise.
Google Vertex AI Agent Builder (rebrandet als Gemini Enterprise Agent Platform) ist seit März 2026 nativ MCP-fähig. Pricing ist pay-per-use mit fünf Komponenten: Agent Engine Runtime (0,0864 USD pro vCPU-Stunde), Session Storage (0,25 USD pro 1.000 Events seit Ende Januar 2026), Vertex AI Search, Modell-Tokens und Memory Bank. AWS Bedrock AgentCore bietet 31 Modelle in Frankfurt, hat aber ein noch komplexeres fünfschichtiges Pricing-Modell (Runtime, Gateway, Memory, Identity, Policy). Ohne FinOps-Disziplin ist der Token- Verbrauch schwer zu antizipieren. Langdock aus Berlin ist die europäische Alternative mit 100 Prozent EU-Hosting, Multi-Modell-Support und 1.500 plus Kunden, besonders relevant für regulierte Branchen.
Aleph Alpha Pharia (Heidelberg), Mistral Large 2 (Paris) und Llama 3.3 70B (Open Weights via Ollama) sind Optionen, wenn Datenhoheit Pflicht ist. Aleph Alpha kann on-premise oder in EU-Cloud laufen, ist Bundeswehr-tauglich und 2026 in Merger-Gesprächen mit Cohere. Mistral Le Chat Enterprise bietet AVV nach EU-Recht mit Hosting in der EU. Llama 3.3 70B läuft auf einer eigenen GPU-Workstation (zwei mal A6000 oder eine H100, 8.000 bis 25.000 Euro Hardware) und liefert in vielen Use-Cases brauchbare Qualität, ohne dass ein einziger Token einen externen Provider verlässt. Mehr Details zur DSGVO-Lage stehen im Guide zu DSGVO-konformen KI-Tools.
Eine Bewertung der wichtigsten Plattformen entlang von sechs Dimensionen, die für deutsche Mittelständler 50 bis 1.000 MA relevant sind. Die Bewertung ist als praktische Heuristik gedacht, nicht als absolute Wahrheit, einzelne Use-Cases können das Bild kippen.

| Tool | DSGVO/EU | Pricing-Klarheit | Lernkurve | Self-Host | ICP-Fit |
|---|---|---|---|---|---|
| n8n | sehr gut | sehr gut | mittel | ja | A+ |
| Langdock | sehr gut | gut | niedrig | nein | A |
| Copilot Studio | gut | mittel | hoch (non-MS) | nein | A (MS-Shops), sonst B |
| Claude via Bedrock EU | gut | sehr gut | mittel | nein | A |
| LangGraph | sehr gut | gut | hoch | ja | B+ (nur mit Devs) |
| Vertex AI | mittel | mittel | mittel | nein | B |
| Make.com | mittel | mittel | niedrig | nein | B |
| Zapier Agents | niedrig | mittel | niedrig | nein | C |
| Aleph Alpha Pharia | sehr gut | auf Anfrage | hoch | ja | A (regulierte Branchen) |
Faustregel aus Pilotprojekten: n8n plus Claude Sonnet 4.6 via AWS Bedrock Frankfurt deckt 70 bis 80 Prozent der Mittelstands- Use-Cases pragmatisch ab. Copilot Studio steigt ein, sobald eine echte M365-Investition existiert. LangGraph kommt ins Spiel, sobald ein internes Engineering-Team existiert und der Use-Case echtes Multi-Agent-Behaviour verlangt.
Statt abstrakter Plattformbewertung sind die folgenden vier Use-Cases der direkte Bezugsrahmen für die meisten Mittelstandsprojekte 2026. Pro Use-Case eine Tool-Empfehlung mit Begründung, eine realistische Implementierungsdauer und die drei häufigsten Stolpersteine.
Eingehende Bestellungen kommen per E-Mail mit PDF-Anhang oder Freitext, ein Agent extrahiert Felder (Kundennummer, Positionen, Mengen, Liefertermin), matcht gegen Stammdaten und legt bei hoher Confidence direkt einen Sales Order in SAP Business One, Business Central oder einem ähnlichen System an. Empfehlung: n8n plus Claude Sonnet 4.6 via Bedrock Frankfurt. Begründung: Die ERP-Konnektivität ist der Hauptaufwand, n8n hat dafür native Nodes oder lässt sich über HTTP-Calls schnell anbinden. Sonnet 4.6 liefert sehr gute strukturierte JSON-Outputs, das ist hier entscheidend. Self-Host auf eigener EU-Maschine löst die DSGVO-Frage. Implementierung: 2 bis 4 Wochen Pilot mit einem Belegtyp und einer Mailbox, 8 bis 12 Wochen für die Produktivnahme mit Stammdaten-Matching und Eskalations-Workflows. Stolpersteine: PDF-OCR-Qualität bei gescannten Belegen schwankt stark (Azure Document Intelligence als Vorstufe planen), Confidence-Schwellen unter 0,85 immer in die Human-Queue, Lieferanten-Artikelnummern versus eigene SKUs brauchen ein Mapping. Tiefe in den Praxisanleitung n8n KI-Agenten.
Eingehende RFQs (Request for Quote) werden gematcht mit aktuellen Konditionen, Lagerverfügbarkeit und Standardpreisen, der Agent erstellt einen Quote-Entwurf und routet zur Innendienst- Freigabe. Empfehlung: n8n plus Claude Sonnet 4.6 plus interner Vektor-Store (Qdrant oder pgvector self-hosted). Bei tiefer SAP-Integration lohnt sich Copilot Studio mit Dataverse zu prüfen, sonst ist eine eigene Lösung kosteneffizienter. Für regulierte Branchen wäre Langdock eine Alternative. Implementierung: 4 bis 8 Wochen Pilot, 3 bis 6 Monate Produktivnahme. Stolpersteine: Preislogik ist oft kundenspezifisch und nicht maschinell erfassbar (kundenspezifische Rabatte, Volumen-Staffeln, Frachtkosten), Verbindlichkeit der Quote darf nie ohne Mensch-Freigabe entstehen, die Stammdatenqualität entscheidet über die Trefferquote des Matching-Schritts. Tiefer in den Großhandels-Kontext im Agentic-AI-Guide für den Großhandel.
Ein RAG-Agent beantwortet Fragen zu interner Doku (Confluence, SharePoint, Drive) mit Quellenangabe. Beispielfragen: wie beantrage ich Spesen, welches SAP-Modul nutzen wir für X, wie ist der aktuelle Stand zum Lieferantenwechsel Müller GmbH. Empfehlung: Langdock wenn EU-Hosting Pflicht ist und kein Self-Build-Anspruch besteht, sonst Copilot Studio plus Dataverse im MS-365-Stack, oder als Maximum an Kontrolle n8n plus Qdrant plus Claude. Implementierung: 1 bis 3 Wochen Pilot, 6 bis 10 Wochen Produktivnahme mit Berechtigungs-Sync. Stolpersteine: der Berechtigungs-Sync ist 80 Prozent des Aufwands, ACLs aus Confluence oder SharePoint müssen im Retrieval-Schritt durchgesetzt werden, sonst leakt der Bot vertrauliche Inhalte. Schlechte Doku-Qualität führt zu Halluzinationen, eine Inventur vor dem Projekt ist Pflicht. Agentic RAG (parallele Retrieval- und Validation- Agenten) ist 2026 das dominante Pattern, aber für den ersten Wurf überdimensioniert, klassisches RAG reicht zum Start.
Eingehende Rechnung wird OCR-t, der Agent matcht gegen Bestellung (PO) und Wareneingangsbeleg (Goods Receipt) und entscheidet: Match führt zu automatischer Freigabe, Toleranzabweichung zu Routing an Sachbearbeiter, harter Mismatch zur Eskalation an Einkauf. Effizienzgewinn dokumentiert: 10 bis 16 Minuten pro Rechnung manuell versus 2 bis 4 Minuten mit Automation. Empfehlung: n8n plus Azure Document Intelligence plus Claude Sonnet 4.6 plus ERP-Connector. Alternativ spezialisierte AP-Lösungen (Rillion, Turian, Mailytica) für reduzierten Eigenaufwand, aber höhere Lizenzkosten. Implementierung: 6 bis 10 Wochen Pilot, 4 bis 6 Monate Produktivnahme. Stolpersteine: Skonto-Logik und Steuersätze (Reverse-Charge, EU-Ausland) müssen sauber abgebildet werden, das interne Kontrollsystem fordert auditfähiges Logging jeder Freigabe, der EU AI Act kann bei automatischen Zahlungsfreigaben über Schwellen zur High-Risk-Klassifikation führen. Mehr Hintergrund im Service Rechnungsprüfung.
Tool-unabhängig braucht jeder produktive Agent dieselben neun Bausteine. Wer einen davon weglässt, baut einen Prototyp, der irgendwann unangenehm überrascht.
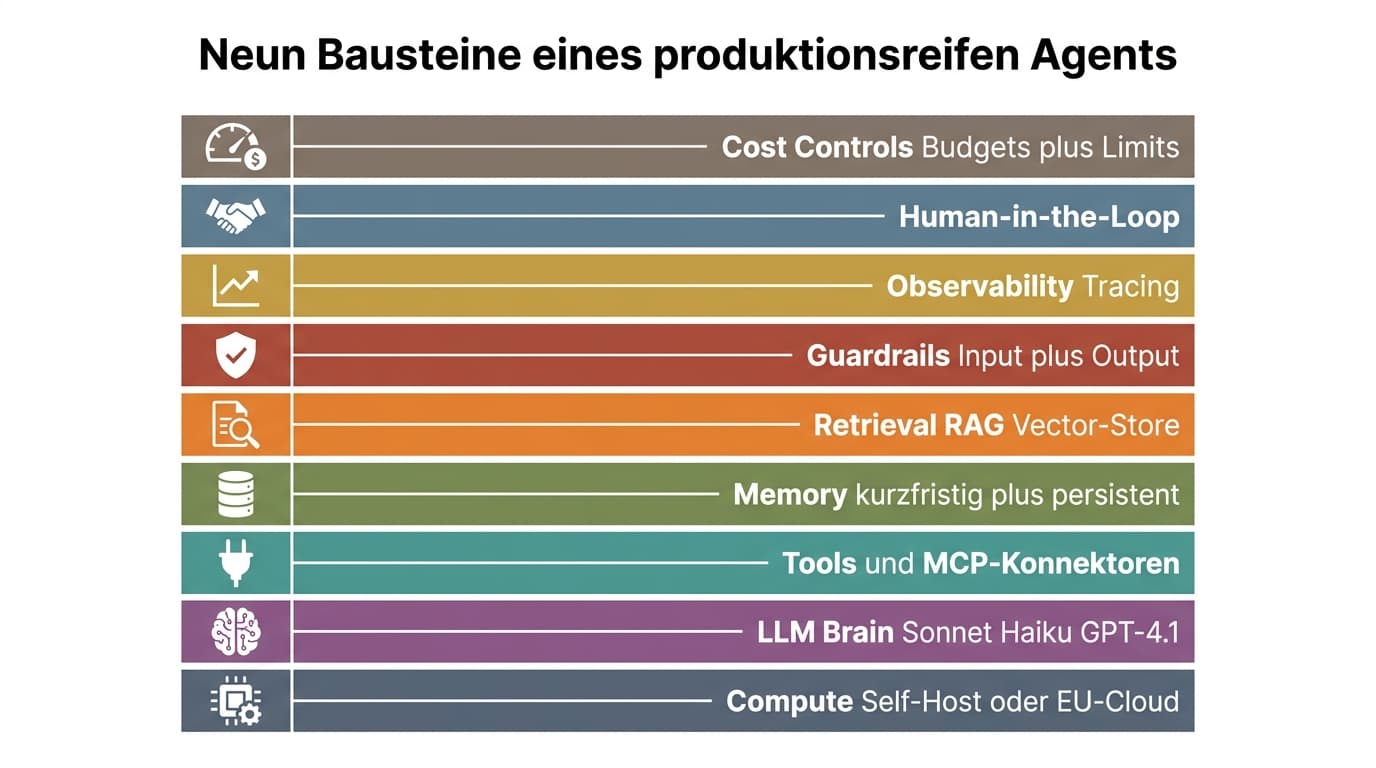
1. Compute: Self-Hosted auf EU-Maschine (Hetzner, IONOS, Mittwald) ab 5 bis 10 Euro pro Monat oder managed in einer EU-Region. Für On-Prem-LLMs eine GPU-Workstation mit 2 mal A6000 oder 1 mal H100. 2. LLM: Auswahl nach Task. Reasoning braucht Sonnet 4.6, Opus 4.7 oder GPT-5.4. Einfaches Routing und Extraction reicht Haiku 4.5 oder GPT-4.1-mini. Latenzkritisch Gemini Flash. Klein anfangen und eskalieren ist die Faustregel. 3. Tools und MCP- Konnektoren: Strukturierte Schnittstellen zu externen Systemen. MCP als Default-Protokoll für neue Tools, seit Dezember 2025 an die Linux Foundation gespendet und mit 78 Prozent Adoption in Enterprise-AI-Teams (Stand April 2026) der De-facto-Standard.
4. Memory: Kurzfristige Conversation-History ist Standard in allen Frameworks, persistente Langzeit-Memory braucht eine eigene Lösung. Vertex Memory Bank kostet 0,25 USD pro 1.000 Events, n8n oder LangGraph lassen sich mit Postgres-Backend self-host konfigurieren. 5. Retrieval (RAG): Vektor-Store (Qdrant, Weaviate, pgvector), Embedding-Modell (text-embedding-3-large oder Cohere embed-multilingual-v3) und Hybrid-Search (Vektor plus BM25) sind 2026 Standard. 6. Guardrails: Input-seitig Prompt-Injection-Detection und PII-Filter (Microsoft Presidio, Guardrails AI), Output-seitig Schema- Validation (Pydantic, Zod) und Halluzinations-Checks. OWASP LLM Top 10 als Mindeststandard.
7. Observability: LangSmith für LangChain-Stacks, Langfuse als Open-Source-Self-Host-Alternative (21k plus GitHub Stars, seit Januar 2026 zu ClickHouse), Arize Phoenix als ebenfalls Open-Source-Lösung. Klassische APM (Datadog, New Relic) erfasst LLM-Spezifika nicht. 8. Human-in-the-Loop: LangGraph hat es nativ über `interrupt()`, n8n über Wait-Nodes, Copilot Studio über Power-Automate-Approvals. Pflicht bei jeder Aktion mit finanzieller, rechtlicher oder kundenseitiger Wirkung in den ersten drei bis sechs Produktionsmonaten. 9. Cost Controls: Token- und Cost-Budgets pro Run und Agent, Loop-Detection, Timeouts und Retry-Limits. Reale Fälle: ein 35-Engineer-Startup zahlte 87.000 USD pro Monat an Claude-Rechnung, weil ein Runaway-Loop wochenlang unbemerkt blieb.
Drei Verschiebungen prägen die Tool-Landschaft im Mai 2026 und sollten in jede Architektur-Entscheidung einfließen.
Das Model Context Protocol, von Anthropic im November 2024 vorgestellt, wurde im Dezember 2025 an die Linux Foundation gespendet (Agentic AI Foundation, co-gegründet von Anthropic, Block und OpenAI). 78 Prozent der Enterprise-AI-Teams haben mindestens einen MCP-Agenten in Produktion. Die Public Server Registry ist von 1.200 (Q1 2025) auf über 9.400 (April 2026) gewachsen. Native MCP-Unterstützung gibt es in Claude, ChatGPT Connectors, Gemini API, Vertex AI Agent Builder, Cursor, Windsurf, JetBrains, Vercel AI SDK, OpenAI Agents SDK. Konsequenz für Mittelständler: MCP-fähige Tools bevorzugen, eigene Daten und Tools als MCP-Server exposeen statt proprietäre Integrationen bauen.
Die Migration auf die Responses API und Conversations API ist kein Endpoint-Tausch, sondern eine grundsätzlich andere Architektur (Object Model, Tool Handling, State, Cost Model). Wer heute noch auf Assistants baut, plant entweder die Migration noch dieses Quartal oder akzeptiert die Notabschaltung. Eine Verlängerung gibt es laut OpenAI nicht.
Die Draft Guidelines der EU-Kommission zur High-Risk- Klassifikation wurden am 19. Mai 2026 veröffentlicht (Konsultation bis 23. Juni 2026). Wichtig: Agentic-Stacks werden als ein High-Risk-System bewertet, nicht komponentenweise. High-Risk-Pflichten greifen ab dem 2. August 2026 für Stand-alone-Systeme, ab dem 2. August 2028 für embedded. Wer einen Agenten baut, der Personalentscheidungen, Zahlungsfreigaben über Schwellen oder Bonitätsbewertungen automatisiert, sollte die Klassifikation früh prüfen lassen.
Aus über zwei Jahren Mittelstandsprojekten kristallisieren sich zehn Muster heraus, die in fast jeder gescheiterten oder schmerzhaft korrigierten Initiative auftauchen.
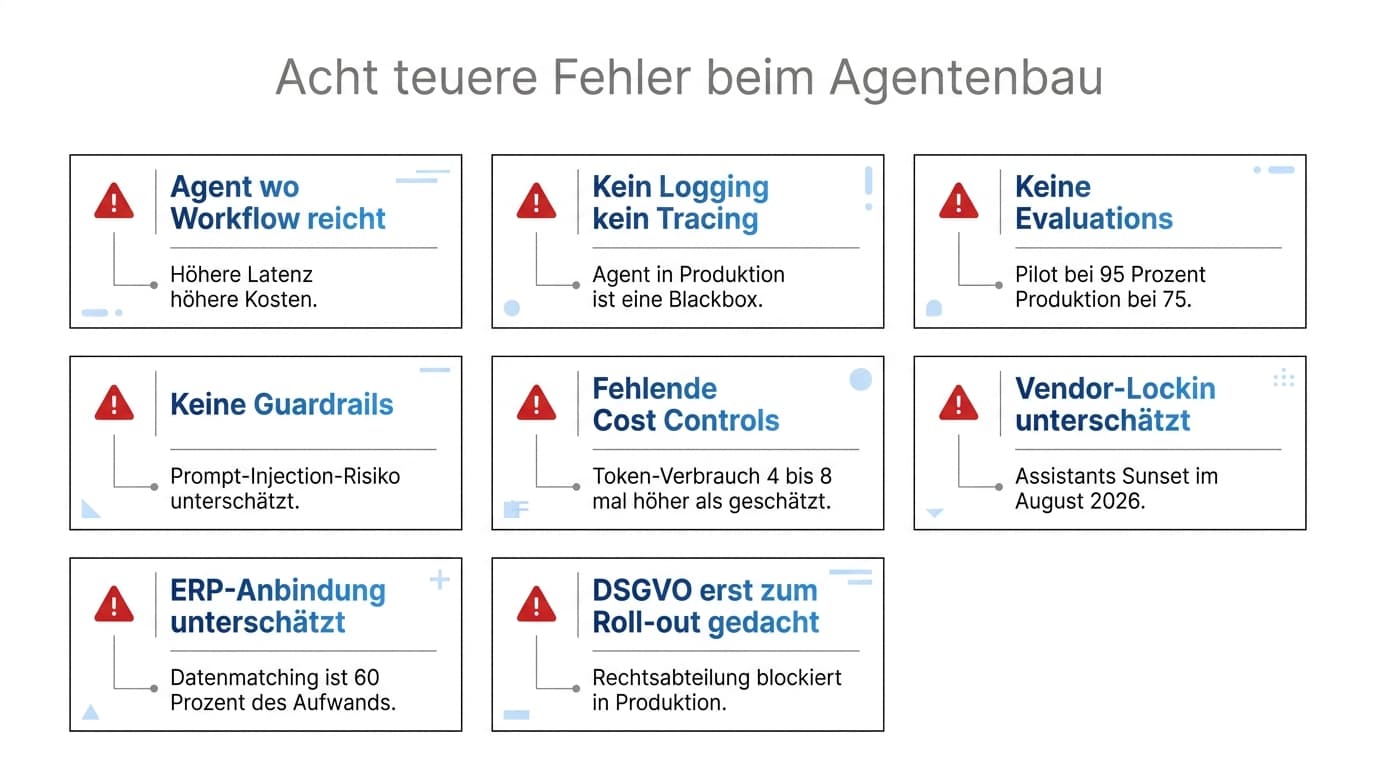
Agent gebaut, wo ein Workflow gereicht hätte. Für eine stabile, deterministische Aufgabe wird ein agentisches System mit Tool-Auswahl, Planning und Reflection gebaut. Resultat: höhere Latenz, höhere Kosten, schwerer zu debuggen. Anthropic-Doktrin: Prompt-Chain schlägt Agent, wenn das Problem es zulässt.
Kein Logging, kein Tracing. Ohne LangSmith, Langfuse oder Arize ist der Agent in Produktion eine Blackbox. Model Drift, Tool-Call-Retry-Loops und Cost-Spikes sind unsichtbar. Klassische APM-Tools erfassen LLM-Spezifika nicht.
Keine Evaluations. Manuelles Testen mit drei Prompts und „sieht gut aus" führt in Produktion bei der 50. E-Mail-Variante zum Bruch. 30 bis 100 reale Beispiele pro Use-Case als Eval-Set und automatisierte Regression-Tests sind Pflicht.
Keine Guardrails. Prompt-Injection ist nicht theoretisch. Eingehende E-Mails enthalten heute schon Versuche, den Agenten zu manipulieren. Ohne Input-Validation kann der Agent Tool-Aufrufe machen, die er nicht sollte.
Fehlende Cost Controls. Agentic-Workflows verbrauchen typisch vier- bis achtmal die Tokens, die man aus User-Prompt plus Final-Response schätzt. Ohne Budget- Limits skalieren Rechnungen leise nach oben.
Vendor-Lock-in unterschätzt. Wer 2024 alles in OpenAI Assistants gebaut hat, migriert 2026 unter Zeitdruck. Tool-Layer (n8n, LangGraph) und Modell-Layer (Bedrock, Vertex, Azure OpenAI als Multi-Provider) entkoppeln.
Pilot überschätzt Produktion. Pilot bei 95 Prozent Accuracy, Produktion bei 75. Faustregel: produktive Genauigkeit liegt 10 bis 15 Prozentpunkte unter dem Pilot. Human-in-the-Loop-Stufen einplanen.
ERP-Anbindung unterschätzt. Bei Use-Cases mit tiefer ERP-Integration ist Konnektivität (RFC, OData, REST) plus Stammdaten-Matching 60 bis 80 Prozent des Aufwands, nicht der „AI-Teil". n8n hat hier strukturelle Vorteile gegenüber reinen AI-Plattformen.
Keine klare Eskalations-Strategie. Drei Stufen sind Standard: Confidence Threshold führt zu Human Review, Tool-Error zu Retry mit Backoff, wiederholtes Scheitern zur Eskalation an Operations mit voller Trace.
DSGVO erst beim Roll-out gedacht. Datenflüsse, Verarbeitungszweck, AVV mit US-Cloud-Provider, DSFA: alles im Pilot ignoriert, in Produktion blockiert die Rechtsabteilung. Vorab klären, dann bauen.
Der pragmatische Einstieg ist nicht „Wir kaufen Tool X". Vier Wochen reichen, um eine seriöse Go-/No-Go-Entscheidung zu treffen, mit echten Daten statt mit Bauchgefühl.
Woche 1: Use-Case-Workshop mit dem Fachbereich. Engpass identifizieren, Erfolgskriterium definieren (zum Beispiel 70 Prozent der Eingangsrechnungen mit Confidence über 0,9 ohne Korrektur), 200 bis 500 historische Beispiele sammeln, davon 20 Prozent als goldenes Testset zurückhalten. Woche 2: PoC im Sandbox. n8n oder gewähltes Tool aufsetzen, LLM-Zugang in EU-Region (Bedrock Frankfurt oder Azure Sweden Central), ein End-to-End-Workflow mit zwei Beispielen. Woche 3: Pilot mit echter Freigabe-Schleife. Workflow mit Hard-Gate auf Mensch, 50 bis 100 echte Vorgänge parallel zum bestehenden Prozess. Vollständiges Logging. Woche 4: Auswertung. Genauigkeit, Confidence-Verteilung, Korrektur-Rate gegen das Erfolgskriterium aus Woche 1. Skalierungs-ROI über zwölf Monate schätzen. Go-/No-Go mit Roadmap zur Produktivnahme (Sicherheitskonzept, Verfahrensdoku, Betriebsrat-Anhörung, Schulung).
Wer tiefer einsteigen will, findet die Spokes verlinkt: die n8n-Praxisanleitung für die konkrete Implementierung mit AI-Agent-Node, Tools und Memory, den Bauplan nach Anthropic für die theoretischen Patterns, den Agentic-AI-Guide für den Großhandel für branchenspezifische Use-Cases und den DSGVO-Leitfaden für die Compliance-Tiefe. Wer den Belegerkennungs- Use-Case lieber an einen Spezialisten vergibt als selbst zu bauen, findet im Service Rechnungsprüfung eine fertige Lösung. Als KI-Automatisierungs-Agentur begleitet Bluebatch deutsche Mittelständler bei diesen Entscheidungen. Sprechen Sie uns an.
Hier finden Sie die Antworten auf häufig gestellte Fragen.
Ein Workflow ist eine deterministische Abfolge von Schritten, in der ein oder mehrere LLM-Aufrufe Felder extrahieren, klassifizieren oder Texte erzeugen. Der Pfad ist fest. Ein Agent ist ein LLM, das selbst entscheidet, welche Tools es in welcher Reihenfolge benutzt, um eine Aufgabe zu lösen. Faustregel: Wenn dein Use-Case als Ablaufdiagramm zeichenbar ist, baue einen Workflow. Wenn der Pfad von der Eingabe abhängt und nicht vorhersehbar ist, baue einen Agenten. Für 70 Prozent der Mittelstands-Use-Cases reicht ein Workflow.
Eine pauschale Antwort gibt es nicht, aber eine Default-Empfehlung: n8n als Orchestrator (self-hosted auf einer EU-Maschine) plus Claude Sonnet 4.6 oder GPT-5.4 als LLM via AWS Bedrock Frankfurt oder Azure OpenAI Sweden Central. Damit deckst du DSGVO, Pricing-Klarheit und ERP-Anbindungstiefe ab. Für MS-365-zentrierte Unternehmen ist Microsoft Copilot Studio die natürliche Wahl, für regulierte Branchen Langdock oder Aleph Alpha Pharia. Pro-Code mit LangGraph oder Claude Agent SDK lohnt sich, wenn ein eigenes Engineering-Team existiert.
Für einen ersten Use-Case sind 15.000 bis 40.000 Euro Setup realistisch (intern oder mit Agenturbegleitung), Software-Lizenzen zwischen 0 Euro (n8n self-hosted) und 3.000 Euro pro Jahr, LLM-API-Kosten von 500 bis 5.000 Euro pro Jahr je nach Volumen. Hosted-Plattformen wie Copilot Studio kosten ab 200 USD pro Monat für 25.000 Credits, wobei Reasoning-Antworten 100x mehr Credits brauchen als Script-Antworten. Bei sauberen Voraussetzungen liegt die Amortisation zwischen 8 und 18 Monaten.
Nein, nicht zwingend. Mit n8n oder Make.com plus AI-Agent-Node kann eine prozessversierte Person ohne tiefe Programmierkenntnisse einen funktionierenden Agenten bauen. Sobald es um Multi-Agent-Systeme, hohe Throughput-Anforderungen oder eng integrierte UI-Frontends geht, lohnen sich Pro-Code-Frameworks wie LangGraph und damit ein Engineering-Team. Eine pragmatische Aufteilung im Mittelstand: n8n als Orchestrator vom Fachbereich gepflegt, Custom-Service für schwierige LLM-Calls vom Engineering oder einem externen Partner.
Fünf Schichten: strukturiertes Output-Format mit Schema-Validierung (falsches Schema führt zu sofortiger Ablehnung), Regel-Validierung auf Plausibilität (Steuersätze, Konten-Existenz, Mengen-Grenzen), Confidence-Gate (alles unter Schwelle geht in die Human-Queue), Audit-Logging jeder Entscheidung und Human-in-the-Loop in den ersten drei bis sechs Produktionsmonaten. Eine direkte LLM-zu-System-Verbindung ohne diese Schichten ist nicht GoBD-konform und in regulierten Umfeldern auch nicht haftungsrechtlich tragfähig.
Die Assistants API wird am 26. August 2026 abgeschaltet. Eine Verlängerung gibt es laut OpenAI nicht. Wer heute auf Assistants baut, muss auf die Responses API und Conversations API migrieren. Das ist kein einfacher Endpoint-Tausch, sondern eine grundsätzlich andere Architektur: Object Model, Tool Handling, State und Cost Model unterscheiden sich. Planen Sie die Migration jetzt, nicht im August. Wer neu startet, baut direkt auf Responses API oder wählt einen anbieterunabhängigen Stack mit n8n oder LangGraph.
MCP ist 2026 der De-facto-Standard für die Anbindung von Tools an LLMs. Seit Dezember 2025 von der Linux Foundation gehostet, 78 Prozent Adoption in Enterprise-AI-Teams, 9.400 plus Server in der Public Registry. Native Unterstützung in Claude, ChatGPT, Gemini, Vertex AI, Cursor, JetBrains, Vercel AI SDK. Konsequenz für die Tool-Wahl: MCP-fähige Plattformen bevorzugen, eigene Daten als MCP-Server exposeen statt proprietäre Integrationen zu bauen. Das reduziert Vendor-Lock-in und macht zukünftige Modell-Wechsel günstiger.