2026 ist das Jahr, in dem aus dem Wort Agent in Pitchdecks endlich produktive Systeme werden. Aber zwischen LinkedIn-Demos und einem laufenden Agent in deinem ERP liegt ein Graben, der mit Hype-Sprache nicht überbrückbar ist. Die meisten Implementierungen scheitern nicht an der Technologie, sondern an einem grundlegenden Missverständnis, was ein Agent eigentlich ist und wann du gar keinen brauchst. Wer den praktischen Weg von der Idee zum laufenden Agent sucht, findet ihn in unserem Leitfaden zum KI-Agenten erstellen.
Genau da setzt das Framework von Anthropic an. Anthropic hat in seinem Engineering-Beitrag "Building Effective Agents" eine Sprache vorgeschlagen, die in der Industrie aktuell die einzige ist, die nicht beim ersten harten Praxiseinsatz auseinanderbricht. Sechs konkrete Patterns, eine harte Definition von Workflow vs. Agent, vier nicht verhandelbare Engineering-Regeln. Klingt trocken. Spart aber sechsstellige Beträge, wenn du es einmal verstanden hast.
Dieser Beitrag tut zwei Dinge. Erstens, er übersetzt das Anthropic-Framework ohne Buzzword-Filter ins Deutsche. Zweitens, er mappt jeden Pattern auf einen konkreten Großhandelsprozess, damit du nach dem Lesen sagen kannst, welche deiner heutigen Probleme ein Workflow lösen würde und welche tatsächlich einen Agent rechtfertigen. Wenn du danach noch der Meinung bist, dein Bestelleingang sei ein Agent-Problem, hast du wenigstens einen sauberen Bauplan.
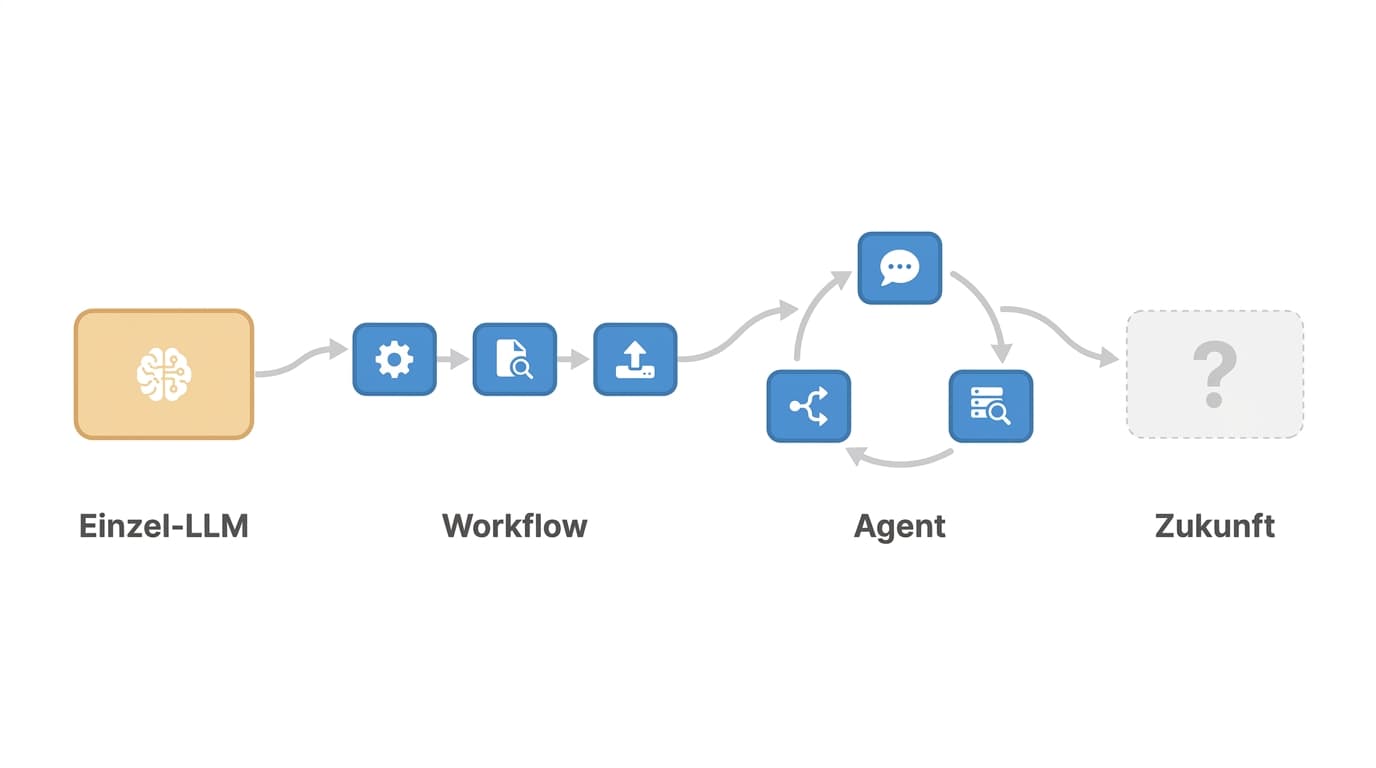
Anthropic zieht den Strich an einer ungewöhnlichen Stelle, und genau dieser Strich ist der ganze Trick. Ein Workflow ist ein System, in dem LLM und Tools über vordefinierte Code-Pfade orchestriert werden. Du kennst die Schritte vorher. A geht nach B, B geht nach C. Das LLM ist eine Komponente in deiner Pipeline, kein Dirigent.
Ein Agent ist ein System, in dem das LLM seinen eigenen Prozess dynamisch in einer Schleife steuert. Es entscheidet selbst, welches Tool als nächstes drankommt, wann es aufhört und ob das Ergebnis gut genug ist. Du gibst ihm ein Ziel, nicht eine Schrittfolge.
Vier Konsequenzen, die du sofort spürst, sobald du den Unterschied ignorierst:
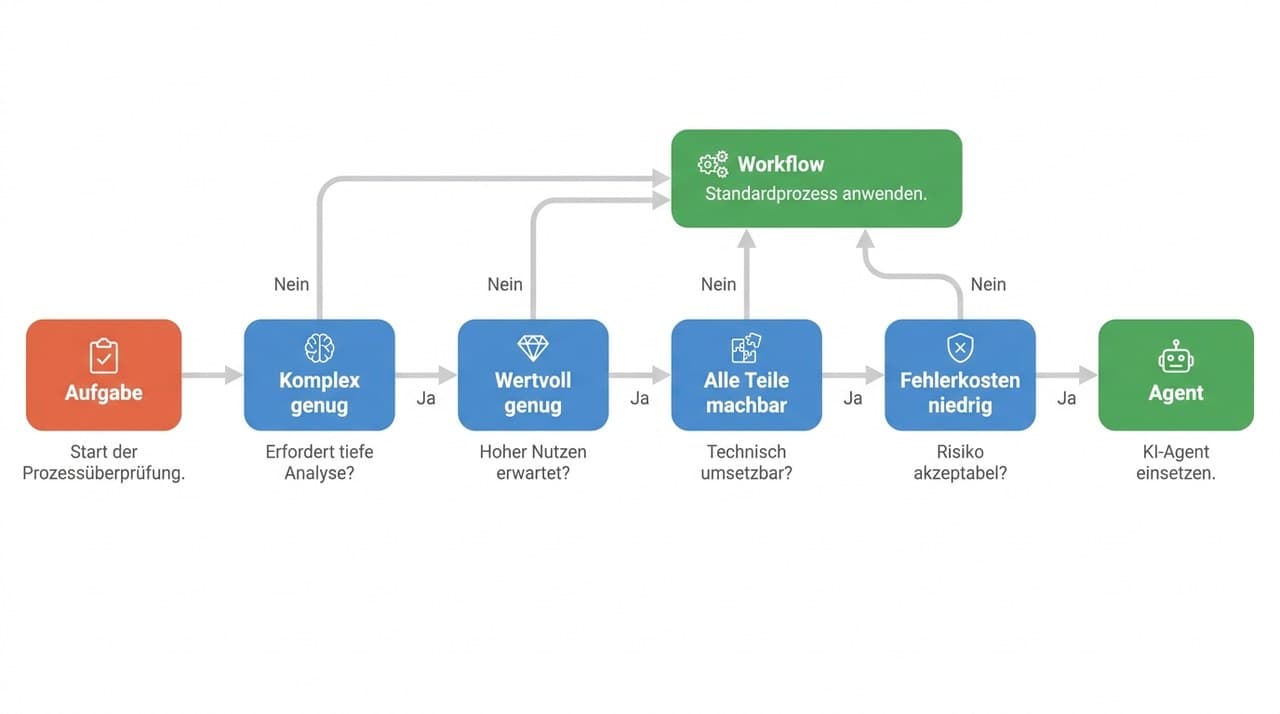
Wenn du den Ablauf auf einem Whiteboard skizzieren kannst, baue einen Workflow. Wenn der Ablauf vom Input abhängt und du keine sinnvolle Skizze hinbekommst, ohne in Wenn-Dann-Bäume zu verfallen, baue einen Agent.
Das klingt simpel und ist es auch. Der Grund, warum die meisten Teams trotzdem in die falsche Richtung laufen, ist FOMO. Agent klingt nach 2026, Workflow nach 2018. Das ist Buzzword-Trauma, kein Engineering-Argument.
Anthropic argumentiert, dass fünf Patterns bereits 80 Prozent der realen Anwendungsfälle abdecken, bevor du überhaupt einen Agent brauchst. Diese Patterns sind keine theoretischen Konstrukte. Sie sind das, was sich bei Tausenden von Implementierungen als robust herausgestellt hat. Wie sie in der Praxis aussehen, zeigt unser Beispielkatalog für KI-Agenten mit konkreten Use-Cases.
Du zerlegst eine Aufgabe in eine Sequenz von LLM-Calls, bei der jeder Output zum Input des nächsten Calls wird. Klassisches Beispiel: ein Mail-Entwurf wird in einem ersten Call geschrieben, in einem zweiten gegen Stil und Compliance geprüft, in einem dritten in HTML gepackt. Drei Schritte, jeder mit einem klaren Auftrag.
Wann du das nimmst: wenn die Aufgabe sich sauber in unabhängige Subaufgaben zerlegen lässt und jede Stufe von der vorherigen profitiert. Wann nicht: wenn die Subaufgaben parallel laufen könnten, dann nimm Parallelization.
Ein Klassifizierer-LLM liest den Input und entscheidet, an welchen spezialisierten Downstream-Prompt es weitergeht. Eine Mail mit "Rechnung falsch" landet beim Billing-Prompt, eine mit "Bug" beim Tech-Support-Prompt, eine mit "Kündigung" bei der Retention-Pipeline.
Wann du das nimmst: wenn du sehr unterschiedliche Eingaben hast, die je eigene Spezialprompts brauchen, und ein einziger generischer Prompt schlechter wäre als spezialisierte. Bonus: du kannst pro Klasse Modelle unterschiedlicher Größe einsetzen.
Anthropic unterscheidet zwei Varianten. Sectioning zerlegt eine große Aufgabe in unabhängige Sub-Tasks, die parallel laufen. Beispiel: fünf Kapitel eines Berichts gleichzeitig schreiben statt nacheinander. Schneller und oft besser, weil jeder Call nur auf seinen Teil fokussiert ist.
Voting lässt denselben Prompt drei oder fünf Mal laufen und nutzt einen Judge-LLM, der die beste Antwort wählt. Klingt verschwenderisch, ist aber bei kritischen Entscheidungen die Differenz zwischen 80 und 98 Prozent Trefferquote. Klassiker bei OCR und Zahlenextraktion.
Ein Lead-Agent zerlegt eine komplexe Aufgabe, delegiert die Teile an Worker-LLMs und synthetisiert deren Ergebnisse zu einer Antwort. Das klingt nach Agent-Pattern und ist es im Lead auch, aber die Worker selbst sind oft simple, spezialisierte Prompts mit klaren Aufträgen.
Wann du das nimmst: wenn du nicht vorher weißt, wie viele Sub-Tasks anfallen werden. Beispiel: eine eingehende Reklamation kann zwei oder zwölf Lieferpositionen betreffen, du weißt es erst nach dem Parsen.
Ein LLM generiert eine Antwort. Ein zweites bewertet sie. Beim Nicht-Bestanden geht es in die Schleife: der Generator bekommt das Feedback und schreibt neu. Bis bestanden oder Reißleine.
Wann du das nimmst: wenn es einen objektivierbaren Quality-Check gibt. Brand-Voice-Compliance, gesetzliche Pflichtangaben, Übersetzungsqualität. Wann nicht: wenn der Critic genauso unsicher ist wie der Generator. Dann kreisen beide ratlos.
Faustregel über alle fünf: Starte mit dem einfachsten Pattern, das deinen Anwendungsfall abdeckt. Wenn ein Prompt reicht, nimm ein Prompt. Wenn eine Sequenz reicht, nimm Chaining. Wenn du erst bei den späteren Patterns landen müsstest, frage dich noch einmal, ob du es wirklich brauchst.
Wenn du nach den fünf Workflow-Patterns immer noch keinen sauberen Bauplan hast, bist du im Agent-Territorium gelandet. Der autonome Loop ist der Ort, an dem ein System komplexe Aufgaben übernimmt, deren Schrittfolge sich erst zur Laufzeit entscheidet.
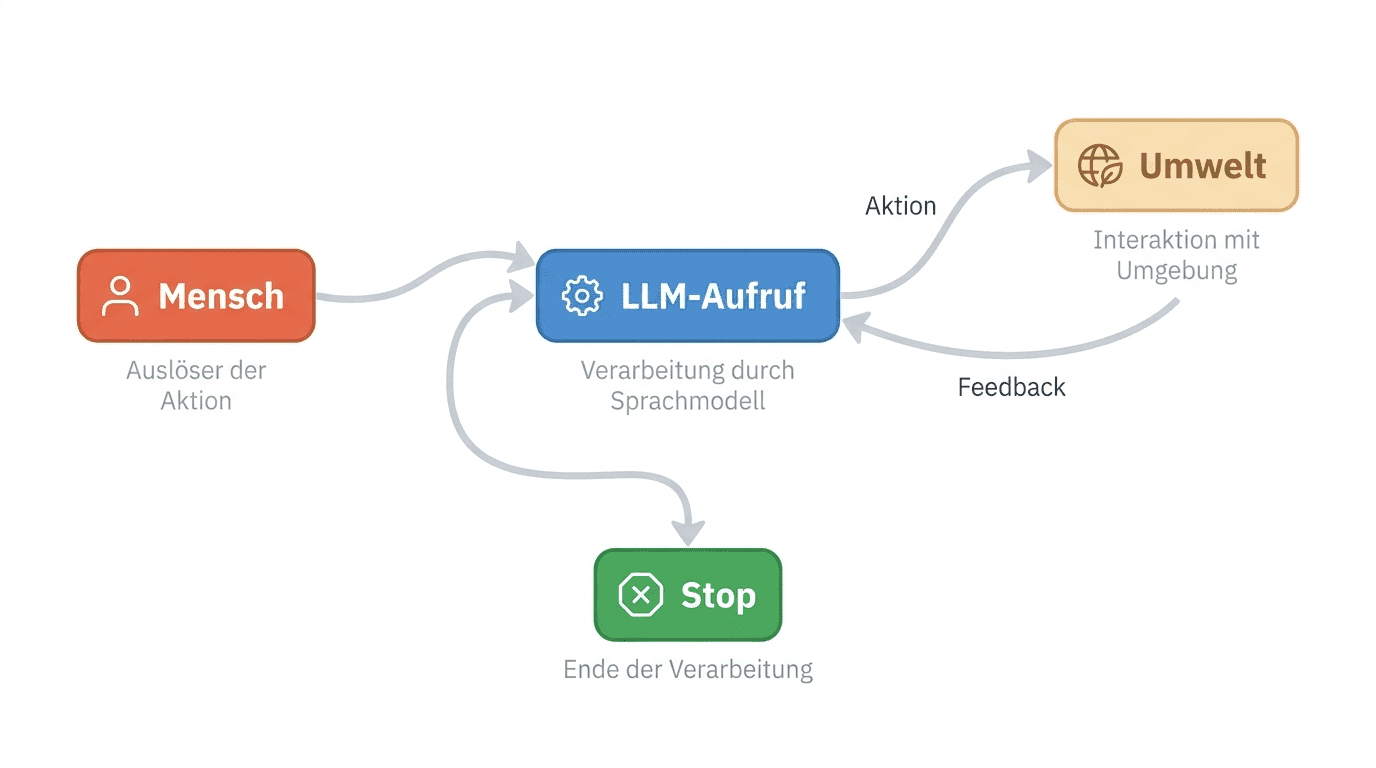
Anthropic beschreibt den Loop als ein simples, fast banales Konstrukt:
Repeat bis Stopp-Bedingung. Mehr ist da formal nicht.
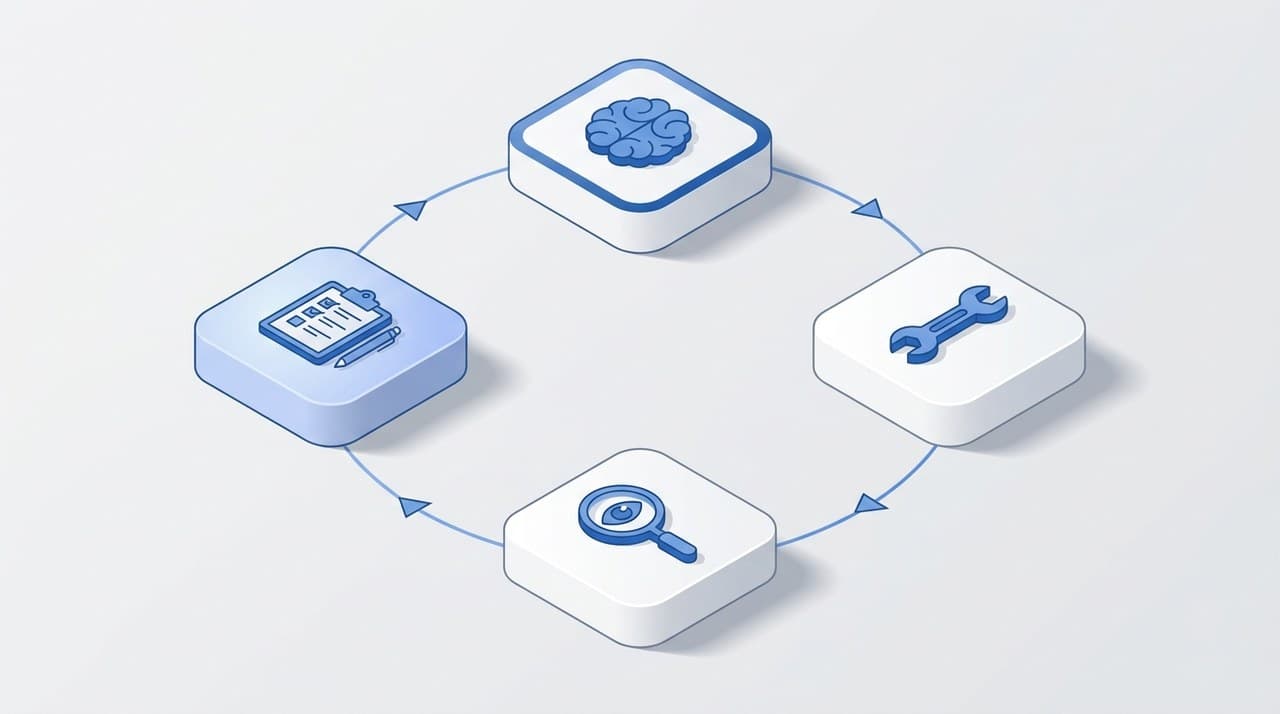
Der Punkt, an dem 90 Prozent der Agent-Implementierungen scheitern, ist nicht die Loop-Mechanik, sondern die Frage: woher weiß der Agent, ob seine letzte Aktion funktioniert hat?
Anthropic nennt das Ground Truth. Ein echter Code-Compiler, der Fehler in Zeile 23 zurückgibt. Ein Datenbank-Query, der wirklich zwölf Zeilen liefert oder eine echte Constraint-Exception wirft. Ein Lieferanten-API, das mit 404 antwortet, wenn die Artikelnummer ungültig ist.
Was passiert, wenn Ground Truth fehlt: der Agent halluziniert sich selbst in eine plausibel klingende, aber falsche Lösung. Er bestätigt seine eigene Annahme, weil ihn niemand widerlegt. Anthropic hat dafür ein hartes Bild: ein Agent ohne Ground Truth ist eine sehr eloquente Endlosschleife.
Drei Voraussetzungen müssen zusammenkommen, sonst ist der Agent-Loop die falsche Wahl:
Fehlt eine dieser drei, baust du einen Workflow. Mit Patterns aus dem vorherigen Kapitel. Ohne Agent. Ohne Loop.
Anthropic schließt sein Framework mit vier Punkten ab, die wie Plattitüden klingen, aber in der Praxis den Unterschied zwischen einem stabilen System und einer Demo-Ruine ausmachen. Wer sie ignoriert, baut entweder zu kompliziert oder zu fragil.
Starte mit einem einzigen Prompt. Einem. Erst wenn du einen konkreten Schmerzpunkt benennen kannst, das Modell verliert die Reihenfolge, die Klassifizierung ist falsch wenn beides drinsteht, die Bewertung schwankt zu stark, baust du ein Pattern dazu.
Die Versuchung, gleich mit einem Orchestrator-Worker-Setup zu starten, weil es nach echtem Engineering aussieht, ist groß. Sie ist trotzdem fast immer falsch. Jeder zusätzliche Pattern bringt eigene Fehlerquellen, Latenz und Debugging-Aufwand. Wenn ein Prompt ausreicht, nimm einen Prompt.
Poka-Yoke ist ein Begriff aus dem Toyota-Produktionssystem. Er bedeutet Mistake-Proofing: gestalte ein Werkzeug so, dass es schwer ist, es falsch zu benutzen. USB-C statt USB-A. Ein Stecker, der nur in eine Richtung passt.
Für LLM-Tools heißt das: klare Funktionsnamen ohne Doppeldeutigkeit, streng typisierte Schemas, sinnvolle Default-Werte und vor allem Fehler, die erklären, was schiefgegangen ist. Wenn dein bestellung_anlegen-Tool bei fehlender Kundennummer einfach null zurückgibt, hast du verloren. Wenn es einen MissingField-Fehler wirft, hat das Modell eine Chance, sich zu korrigieren.
Verstecke nie die Gedanken des Agents. Jeder Reasoning-Schritt, jeder Tool-Call mit seinen Parametern, jedes Ergebnis muss geloggt sein, durchsuchbar und nachvollziehbar. Sonst kannst du nicht debuggen, warum der Agent gestern eine andere Entscheidung getroffen hat als heute.
Praktisch heißt das, du brauchst von Tag eins ein Observability-Setup: Traces pro Anfrage, strukturierte Logs der Tool-Aufrufe, Versionierung der Prompts. Ohne diese Basis ist jeder Agent in Produktion ein Lotteriespiel.
Lass den Agent nicht alleine eine Mail an einen Kunden rausschicken. Lass ihn nicht alleine eine Datenbank-Zeile löschen. Lass ihn nicht alleine eine Bestellung ans ERP übergeben.
Bei jeder Aktion, deren Reversibilität fragwürdig ist oder deren Wirkung außerhalb deines Sandkastens liegt, muss der Agent stoppen und freigeben lassen. Das ist keine Schwäche, das ist Produkt-Engineering. Anthropic formuliert es so: Reversibel oder Mensch.
Es gibt einen guten Grund, warum die meisten erfolgreichen Agent-Implementierungen 2026 im Coding-Umfeld zu finden sind, nicht im Marketing oder im Vertrieb. Coding ist die Domäne, in der die drei Bedingungen für einen funktionierenden Agent perfekt zusammenkommen.
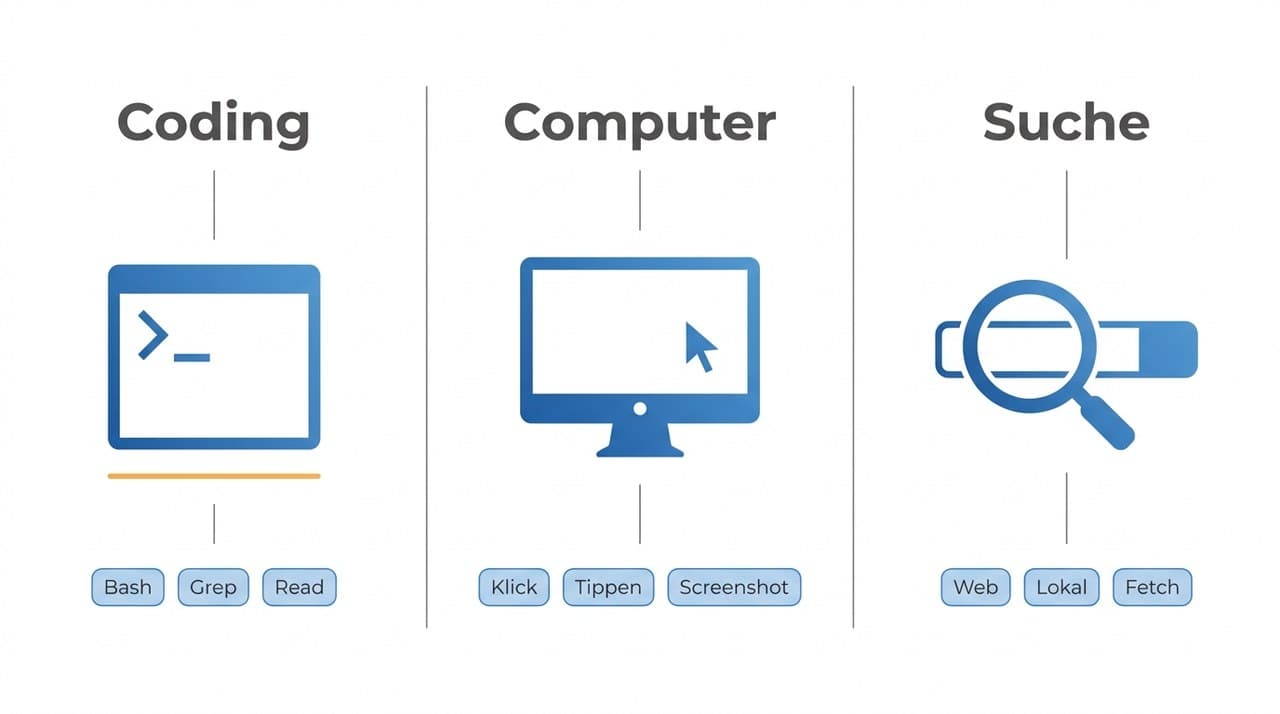
Anthropic nennt das den Tests-grün-Effekt. Coding hat ein eingebautes Pass/Fail-Signal, das in den meisten anderen Domänen erst aufwendig konstruiert werden müsste.
Die spannende Frage ist nicht warum funktioniert Coding so gut, sondern wie reproduziere ich diese drei Eigenschaften in meiner Domäne. Wenn du es schaffst, in deinem Prozess ein klares Pass/Fail-Signal zu definieren, einen serialisierbaren Zustand zu finden und Iterationen ohne menschliches Eingreifen zu erlauben, hast du dort dieselben Bedingungen wie beim Coding.
Genau das ist die Brücke ins nächste Kapitel: was ist im Großhandel das Äquivalent zur grünen Testsuite? Welche Prozesse haben dieses Pass/Fail-Signal eingebaut, welche nicht? Wo musst du die Ground Truth selbst bauen, bevor ein Agent überhaupt eine Chance hat?
Jetzt der eigentliche Praxisteil. Die sechs Patterns von Anthropic, jeweils auf einen typischen Großhandelsprozess gemappt, mit klarer Aussage darüber, welche Ground Truth den Agent erst überhaupt arbeitsfähig macht.
| Pattern | Großhandels-Use-Case | Konkretes Beispiel | Ground Truth |
|---|---|---|---|
| Prompt Chaining | Angebot aus Anfrage erzeugen | Mail-Klassifizierung → Preis-Lookup im ERP → Angebotstext → PDF-Render | Angebot trifft Marge und Lieferzeit |
| Routing | Mail-Triage im Vertriebspostfach | Bestellung vs. Reklamation vs. Lieferanfrage → spezialisiertes Folge-Prompt | Vorgang landet beim richtigen Sachbearbeiter |
| Parallelization (Sectioning) | Lieferanten-Stammdaten anreichern | USt-ID, Adresse, Branche, Bonität parallel ziehen | Felder gegen externe Quellen validieren |
| Parallelization (Voting) | OCR auf Eingangsrechnungen | Drei OCR-Passes, Judge entscheidet bei Konflikt | Rechnungssumme passt zur Bestellung |
| Orchestrator-Workers | Multi-Channel-Bestelleingang | Lead verteilt ERP-Check, Verfügbarkeit, Bonität, Versandweg auf Worker | Auftrag steht buchungsbereit im ERP |
| Evaluator-Optimizer | PIM-Produktbeschreibungen | Generator schreibt, Critic prüft Brand-Voice und Pflichtangaben, Loop bis Pass | Text besteht Compliance-Checkliste |
| Autonomer Agent-Loop | Sonderteil-Recherche, Reklamation | Agent iteriert über PIM, ERP, Lieferanten-Portale bis Treffer | Trefferquote im Retrospektiv-Audit |
Eine Kundenanfrage kommt per Mail rein. Schritt eins klassifiziert, ob es eine Angebotsanfrage ist und welche Artikelnummern erwähnt sind. Schritt zwei holt die aktuellen Preise und Lieferzeiten aus dem ERP. Schritt drei formuliert den Angebotstext im euren Stil. Schritt vier rendert das PDF und legt es im DMS ab. Vier saubere LLM-Calls in Reihe, kein Loop nötig. Ground Truth: das System validiert am Ende, dass Marge und Lieferzeit innerhalb der freigegebenen Range liegen, sonst geht es in die Freigabe-Schleife. Mehr dazu in unserem Artikel zur automatischen Angebotserstellung im Großhandel.
Eingangsrechnungen kommen als PDFs rein, oft schlecht gescannt. Ein einziger OCR-Pass liegt bei 80 bis 85 Prozent Trefferquote auf den kritischen Feldern (Betrag, USt-ID, Lieferantennummer). Drei parallele Passes mit unterschiedlichen Modellen plus ein Judge-LLM, der bei Konflikten die plausibelste Variante wählt, schiebt die Genauigkeit über 97 Prozent. Ground Truth: am Ende muss die Rechnungssumme exakt zur dazugehörigen Bestellung passen, sonst wird geflaggt.
Eine Bestellung kommt per EDI, Mail oder Telefonnotiz rein. Ein Lead-Prompt parst sie und entscheidet, was alles geprüft werden muss: Artikelverfügbarkeit, Kundenbonität, passender Versandweg, Sonderkonditionen. Diese Checks laufen parallel als Worker-Prompts. Der Lead synthetisiert die Ergebnisse zu einer Buchungs-Empfehlung. Wenn alle vier Worker grün geben, wandert die Bestellung automatisch ins ERP. Wenn einer rot meldet, kommt sie in die Inbox der Sachbearbeitung mit klarer Begründung. Vertieft in unserem Beitrag Bestellungen erfassen automatisieren.
Der häufigste Fehler in Großhandelsprojekten: Wir bauen einen Universal-Agent, der alles im Bestelleingang macht. Das klingt elegant, ist aber fast immer der falsche Bauplan. Du verlierst die Debuggability, weil jeder Fehler in einem dreißig-Schritte-Loop versickert. Du verlierst die Kosten-Kontrolle, weil ein Agent gerne zehn Mal nachfragt, wo ein Workflow zwei Calls braucht. Und du verlierst die Compliance, weil deine Auditoren keine Antwort auf warum wurde diese Bestellung gebucht bekommen.
Die richtige Antwort ist fast immer eine Komposition: für die meisten Schritte ein Workflow-Pattern, an einer oder zwei klar abgegrenzten Stellen ein kleiner Agent-Loop. Nicht ein großer Agent für alles.
Wer das Anthropic-Framework einmal verinnerlicht hat, baut anders. Statt wir machen einen Agent steht am Anfang die Frage, ob die Aufgabe überhaupt einen Agent rechtfertigt oder ob ein simples Pattern reicht. Statt schau wie smart das System ist steht am Ende die Frage, ob es nachvollziehbar, debugbar und stoppbar ist.
Drei Fragen, die du vor dem ersten Code-Commit beantworten können musst. Wenn eine davon nein oder unklar ist, gehe zurück ans Whiteboard.
Wer alle drei mit ja beantwortet, hat einen Agent-Bauplan. Wer nicht, hat einen Workflow-Bauplan. Beides ist okay. Nur das Vermischen ist teuer.
Du hast einen konkreten Prozess im Großhandel, bei dem du nicht sicher bist, ob er ein Workflow oder ein Agent werden soll? 30 Minuten Erstgespräch, wir nehmen das Pattern auseinander, du nimmst eine begründete Empfehlung mit, ohne Verkaufsdruck. Einfach Termin buchen oder weiter lesen in unserem Beitrag zu Agentic AI im Großhandel.
